


オーディオスペクトル解析は、音響信号を周波数成分に分解してその特性を詳細に調べるプロセスです。
この分析は音楽制作、音声処理、音響工学、さらには心理音響学など多岐にわたる分野で重要な役割を果たします。
オーディオスペクトル解析を行うことで、音のピッチ、ボリューム、質感などの特性を可視化し、より深い理解を得ることができます。
ほとんどのマスタリングソフトでもこの機能は付属していますが、今回はPythonのライブラリであるlibrosaを使って視覚化。
そしてその見方や分析方法、オーディオスペクトル解析から何がわかるのか?までみていきましょう。
オーディオスペクトル解析の基本
オーディオ信号は、時間によって変化する音圧の波形として捉えられます。
この波形は様々な周波数成分の合成であり、スペクトル解析によってこれらの成分を分離し観察することができます。
スペクトル解析の基本的な手法としては、フーリエ変換があります。
これにより、時間領域の信号を周波数領域に変換し、どの周波数の成分がどれくらいの強度で含まれているかを知ることができます。
スペクトログラムの利用
スペクトログラムはスペクトル解析の結果を色や明るさで表した図で、時間軸に沿って変化する周波数成分の強度を視覚的に示します。
高い周波数は図の上部、低い周波数は図の下部に位置し、色の濃淡や明るさで強度が示されます。
スペクトログラムを用いることで、音の質感の変化、音声の明瞭さ、楽器の音色などを分析することが可能です。
実践的な応用例
オーディオスペクトル解析は、音楽制作においても非常に有用です。
たとえば、ミキシングプロセスにおいて、楽器間の周波数の衝突を特定し、イコライザーを使って調整する際に役立ちます。
また、ノイズリダクションやオーディオのクリアリング、さらには音声認識システムの改善など、さまざまな場面で活用されています。
これらは熟練のエンジニアであれば耳で聞いて脳内で解析することができます。
しかし、やはり教育面において、論理的に誰かに解説、そして伝えるためには非常に重要な解析ツールであるといえます。
Pythonを用いたスペクトル解析
Pythonプログラミング言語では、librosaのようなライブラリを使用して容易にオーディオスペクトル解析を実行できます。
このライブラリはオーディオファイルの読み込み、フーリエ変換、スペクトログラムの生成といった一連のプロセスをサポートしています。
以下に、簡単なPythonコードの例を示します。
まずはライブラリをインストールしてください。
pip install librosaアナコンダを使った仮想環境での個別インストールは
conda install -c conda-forge librosa
import librosa
import librosa.display
import matplotlib.pyplot as plt
# オーディオファイルを読み込む
audio_path = 'path/to/your/audiofile.wav'
audio, sr = librosa.load(audio_path)
# 短時間フーリエ変換(STFT)を使用してスペクトログラムを計算
spectrogram = librosa.stft(audio)
spectrogram_db = librosa.amplitude_to_db(abs(spectrogram))
# スペクトログラムをプロット
plt.figure(figsize=(12, 6))
librosa.display.specshow(spectrogram_db, sr=sr, x_axis='time', y_axis='log')
plt.colorbar(format='%+2.0f dB')
plt.title('Spectrogram')
plt.show()
こちらでプロットできます。
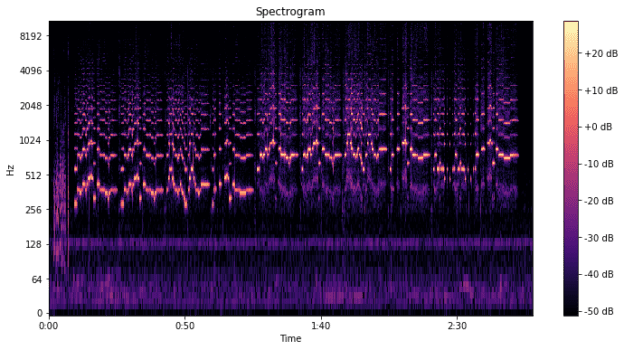
プロットにはmatplotlibを使っていますので、matplotlibのインストールもお忘れなく。
一緒にインストールする場合はコマンドでこちらを叩いてください。
pip install librosa matplotlib
librosa.loadはデフォルトでオーディオをモノラルに変換し、サンプリングレートを22,050Hzに変更します。
必要に応じてこれらの設定を変更することができます。
オーディオファイルの形式によっては、追加でデコーダ(例えば、ffmpeg)が必要になることがあります。
なぜモノラルに変換するのか?
モノラルに変換して解析するのにはいくつかの理由があります。
モノラルへの変換のメリット
- 処理の単純化: モノラルデータは一つのチャンネルのみを含むため、ステレオデータ(二つのチャンネル)に比べて処理が単純です。特に、音声解析や特徴抽出において、処理の複雑さを減らすことができます。
- 計算コストの削減: モノラルデータはステレオデータの半分のデータ量しか持たないため、処理に要する計算コストが少なくなります。これは大量のデータを処理する場合や、計算リソースが限られている環境で特に有利です。
- 一貫性の確保: 音楽トラックや録音は、録音方法や音源によって左右のチャンネルに異なる情報が含まれることがあります。モノラル化することで、これらの差異を無視し、一貫した解析を行うことができます。
- 特定のアプリケーションでの利便性: 音声認識や特定の種類の音響解析では、チャンネル間の違いよりも音声や音響イベント自体の特徴が重要になることが多いです。このような場合、モノラル化は有効なアプローチです。
ステレオでの解析ももちろん可能です。
次にステレオのまま解析する方法をみていきましょう。
ステレオデータの処理方法
LibROSAを使用してステレオデータをそのまま扱うには、librosa.load関数のmono=Falseオプションを指定します。
以下に、ステレオオーディオファイルを読み込むためのコード例を示します。
import librosa
import librosa.display
import matplotlib.pyplot as plt
# ステレオオーディオファイルを読み込む
audio_path = 'path/to/your/stereo-audiofile.wav'
audio, sr = librosa.load(audio_path, mono=False)
# 左チャンネルと右チャンネルを分離
left_channel, right_channel = audio[0], audio[1]
# 左チャンネルの波形を表示(右チャンネルも同様に扱えます)
plt.figure(figsize=(12, 4))
librosa.display.waveshow(left_channel, sr=sr)
plt.title('Left Channel Waveform')
plt.xlabel('Time (seconds)')
plt.ylabel('Amplitude')
plt.show()
ステレオオーディオファイルを読み込んで、左右のチャンネルを分離しています。
ステレオデータを扱う場合は、両方のチャンネルを個別に分析するか、必要に応じてモノラルに変換してから分析を行うことができます。
スペクトログラムの読み方
スペクトログラムは、時間軸(横軸)、周波数軸(縦軸)、そして音の強度(色の濃淡や明るさ)で構成されています。
- 時間軸: 横軸は時間を表し、オーディオファイルの開始から終了までの時間的進行を示します。
- 周波数軸: 縦軸は周波数を表し、通常は低い周波数(低音)が下部に、高い周波数(高音)が上部に配置されます。
- 強度: 色の濃淡や明るさは、特定の時間と周波数での音の強度(振幅)を表します。通常、明るい部分や濃い色は強い音を、暗い部分は弱い音を示します。
スペクトログラムによる分析
スペクトログラムを分析することで、以下のような情報を得ることができます。
- 音のピッチや音高の変化: 音楽やメロディーでは、高いピッチはスペクトログラムの上部、低いピッチは下部に表示されます。これにより、音楽のメロディーや音高の変化を視覚的に追跡することができます。
- リズムとテンポ: ビートやリズムのパターンは、時間軸に沿った繰り返しパターンとして現れます。これにより、曲のリズム構造やテンポを分析することができます。
- 音響テクスチャと音色: 楽器や声の音色は、周波数範囲にわたるエネルギーの分布によって異なります。スペクトログラムを通じて、異なる楽器や声の特徴を識別し、音色を分析することができます。
- ダイナミクスの変化: 音の強弱やダイナミクスの変化は、スペクトログラム上での強度の変化として観察できます。これにより、楽曲の表現力や感情的な強度を分析することが可能です。
- ノイズや不要な音の特定: スペクトログラムはノイズや不要な音(例えば、ヒスノイズやポップ音)を特定するのにも有用です。これらは通常、特定の周波数帯域に不規則なパターンとして現れます。
スペクトログラムを使った具体的な応用
- 音楽制作: ミキシングやマスタリングの過程で、スペクトログラムを使って楽器間の周波数の衝突を特定し、イコライザーを用いて調整することができます。
- 音声認識: 音声の明瞭性や発音の特徴を分析し、音声認識システムの精度を向上させることができます。
- 音響学的研究: 自然音や都市の騒音など、さまざまな環境音の特性を分析し、音響環境の改善に役立てることができます。
波形と一緒にプロット
この方法でオーディオの波形とスペクトログラムを同時に視覚化することにより、音の時間的な変化と周波数コンテンツの関連性をより深く理解することができます。
import librosa
import librosa.display
import matplotlib.pyplot as plt
# オーディオファイルを読み込む
audio_path = 'path/to/your/audiofile.wav'
audio, sr = librosa.load(audio_path)
# 波形をプロット
plt.figure(figsize=(12, 8))
plt.subplot(2, 1, 1) # 2行1列のグリッドの上部
librosa.display.waveshow(audio, sr=sr)
plt.title('Audio Waveform')
plt.xlabel('Time (seconds)')
plt.ylabel('Amplitude')
# スペクトログラムを計算
spectrogram = librosa.stft(audio)
spectrogram_db = librosa.amplitude_to_db(abs(spectrogram))
# スペクトログラムをプロット
plt.subplot(2, 1, 2) # 2行1列のグリッドの下部
librosa.display.specshow(spectrogram_db, sr=sr, x_axis='time', y_axis='log')
plt.colorbar(format='%+2.0f dB')
plt.title('Spectrogram')
plt.xlabel('Time (seconds)')
plt.ylabel('Frequency (Hz)')
plt.tight_layout()
plt.show()
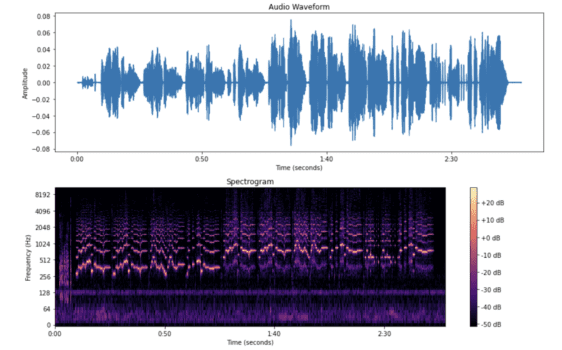
個人的にはイコライザーの使い方など、本来エンジニアが感覚と経験で行うことの教育目的での使用で使いたいと思っています。
みなさんはどのような目的で使用しますか?
周波数解析
librosaは周波数解析も優れていて同様にプロット処理することが可能です。
import librosa
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
# オーディオファイルを読み込む
audio_path = 'path/to/your/audiofile.wav'
audio, sr = librosa.load(audio_path)
# ピッチを抽出
pitches, magnitudes = librosa.piptrack(y=audio, sr=sr)
# タイムフレームごとに最も大きなマグニチュードのピッチを抽出
pitch = []
for t in range(pitches.shape[1]):
index = magnitudes[:, t].argmax()
pitch.append(pitches[index, t])
pitch = np.array(pitch)
# ピッチをプロット
plt.figure(figsize=(12, 6))
plt.plot(pitch)
plt.title('Pitch Tracking')
plt.xlabel('Time')
plt.ylabel('Pitch (Hz)')
plt.show()
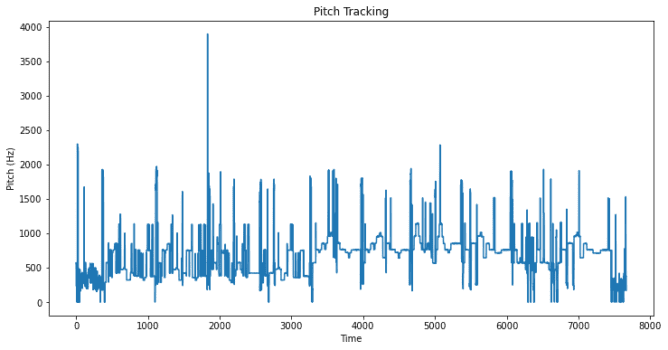
まとめ:サンプルコード
これらすべてを一つにまとめた最終コードがこちら
import librosa
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
# オーディオファイルを読み込む
audio_path = 'path/to/your/audiofile.wav'
audio, sr = librosa.load(audio_path)
# 波形をプロット
plt.figure(figsize=(12, 10))
plt.subplot(3, 1, 1) # 3行1列のグリッドの最上部
librosa.display.waveshow(audio, sr=sr)
plt.title('Audio Waveform')
plt.xlabel('Time (seconds)')
plt.ylabel('Amplitude')
# スペクトログラムを計算してプロット
spectrogram = librosa.stft(audio)
spectrogram_db = librosa.amplitude_to_db(abs(spectrogram))
plt.subplot(3, 1, 2) # 3行1列のグリッドの中部
librosa.display.specshow(spectrogram_db, sr=sr, x_axis='time', y_axis='log')
plt.colorbar(format='%+2.0f dB')
plt.title('Spectrogram')
plt.xlabel('Time (seconds)')
plt.ylabel('Frequency (Hz)')
# ピッチを抽出してプロット
pitches, magnitudes = librosa.piptrack(y=audio, sr=sr)
pitch = []
for t in range(pitches.shape[1]):
index = magnitudes[:, t].argmax()
pitch.append(pitches[index, t])
pitch = np.array(pitch)
plt.subplot(3, 1, 3) # 3行1列のグリッドの最下部
plt.plot(pitch)
plt.title('Pitch Tracking')
plt.xlabel('Time')
plt.ylabel('Pitch (Hz)')
plt.tight_layout()
plt.show()